1. Internet of Things (IoT) App Integration
The IoT is far from a new concept. But the rise in mobile penetration across a broad range of sectors and categories has created seemingly endless opportunities for the Internet of Things. People have grown accustomed to using technology to improve their everyday life. The IoT describes the growing network of devices connected to the Internet, providing convenience and automated control to consumers. Smart home technology is a perfect example of the rise in IoT and mobile app development. Mobile apps can be used to adjust the thermostat in a house from a remote location, lock or unlock a front door, and connect to home security systems. Refrigerators and other household appliances can also be connected to mobile apps. The global Internet of Things market to reached $318 billion in 2023. $226 billion of that comes from software, like mobile apps.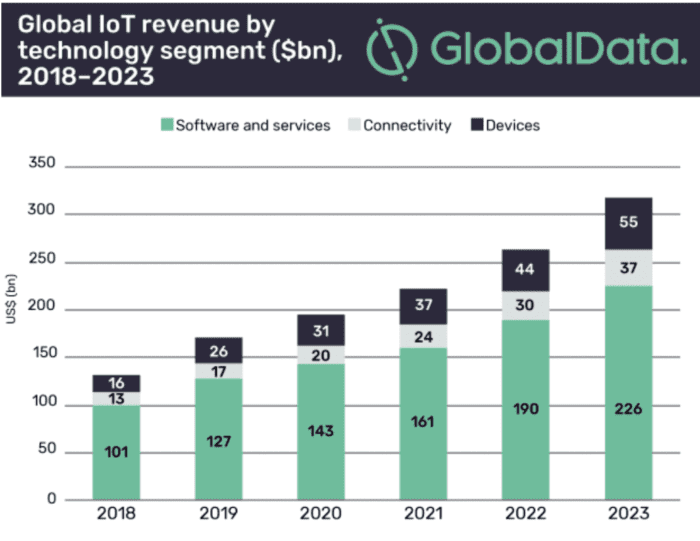 That’s a 58% increase from 2020. As you can see from the graph, the IoT is poised for steady growth in the coming years with software leading the way. The number of IoT devices out there is growing,
According to Statista, the revenue from technology associated with the Internet of Things will eclipse 1.6 trillion by 2025.
In 2024, I expect to see more mobile app development with the IoT in mind. Household devices, automobiles, display devices, smart devices, and healthcare are all markets to keep an eye on.
That’s a 58% increase from 2020. As you can see from the graph, the IoT is poised for steady growth in the coming years with software leading the way. The number of IoT devices out there is growing,
According to Statista, the revenue from technology associated with the Internet of Things will eclipse 1.6 trillion by 2025.
In 2024, I expect to see more mobile app development with the IoT in mind. Household devices, automobiles, display devices, smart devices, and healthcare are all markets to keep an eye on.
2. Apps For Foldable Devices
It feels like a lifetime ago, but one of my first mobile phones was a flip phone. Mobile phones have clearly changed over the last decade. Touch screens with one or no buttons have taken over the market. But over the last couple of years, foldable devices have begun making a comeback. 2019 saw the release of foldable devices like the Samsung Galaxy Fold, the Huawei Mate X, and the new Motorola Razr. These smartphones fold to compress or expand the screen size based on user preferences. For example, a user might make a call with the device closed, but watch a video on a larger screen by unfolding the device. From an app development perspective, resellers and content creators need to account for these devices when building or updating an app. The idea is that an app should seamlessly adjust its display as the screen folds or unfolds. Right now, foldable devices are just a sliver of the overall smartphone market share. But this will change in the coming years. According to a 2019 study by USA Today, 17% of iPhone users and 19% of Android users are excited about buying a phone with a foldable design. According to Statista, roughly 3.2 million foldable phones were shipped in 2019. This forecast is expected to reach 50 million units by 2023. This will obviously be a big year for foldables, which means app developers must plan accordingly.3. 5G Technology
The rollout of 5G will have a major impact on 2024 app trends. For developers, resellers, and creators, this technology is poised to change the way mobile applications are used and created. Take a look at the expected growth of 5G smartphone connections over the next four years.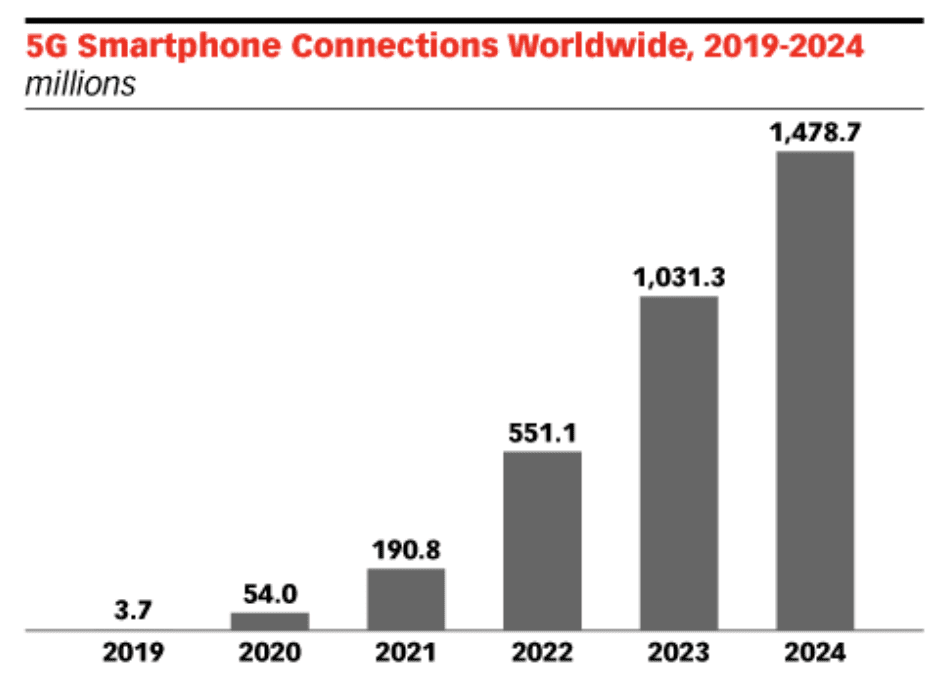 2021 had roughly 3.5 times more 5G connections than in 2020. These connections will nearly triple again in between 2022 and 2024.
What does this mean for mobile app development?
Speed and efficiency will drastically improve. In fact, 5G is expected to deliver a 10x decrease in latency, while boosting network efficiency and traffic capacity. Compared to 4G, 5G will be up to 100 times faster, depending on the mobile network operator.
The penetration of 5G will ultimately boost the functionality of mobile apps. This will allow developers to add new features to apps without negatively affecting the app’s performance.
Developers and mobile app resellers should also use 5G network speed during the testing and development stages of building an app.
2021 had roughly 3.5 times more 5G connections than in 2020. These connections will nearly triple again in between 2022 and 2024.
What does this mean for mobile app development?
Speed and efficiency will drastically improve. In fact, 5G is expected to deliver a 10x decrease in latency, while boosting network efficiency and traffic capacity. Compared to 4G, 5G will be up to 100 times faster, depending on the mobile network operator.
The penetration of 5G will ultimately boost the functionality of mobile apps. This will allow developers to add new features to apps without negatively affecting the app’s performance.
Developers and mobile app resellers should also use 5G network speed during the testing and development stages of building an app.
4. Development For Wearable Devices
Wearable technology has been trending upward for years now as well. This isn’t necessarily a breakthrough in the market. We’ve seen smartwatches, trackers, and fitness bands for a while now. But wearable devices have yet to reach their full potential. Take a look at this graph from eMarketer about the penetration of wearables in the United States.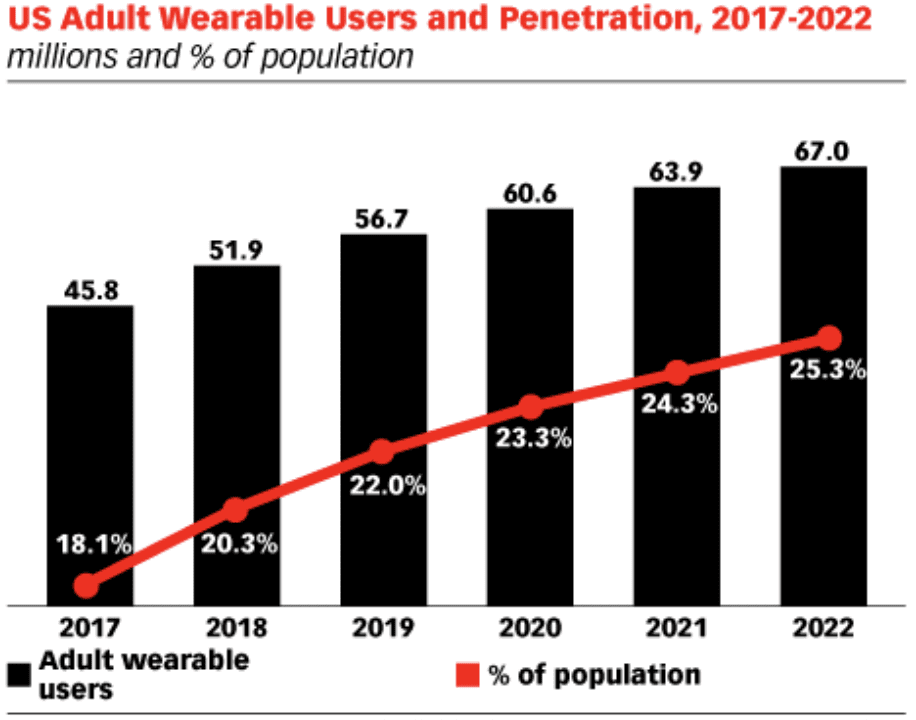 While we’re not seeing a staggering jump year-year-over year, the growth is still steady. The wearables trend has changed and will continue to change the way that mobile apps get developed.
For instance, Apple made a big announcement about wearables and app integration at WWDC 2019. The new watchOS 6 has brought the Apple App Store to Apple Watch. Independent apps are being built specifically for these devices. This has created an enormous opportunity for app resellers and content creators.
In 2024, more mobile apps will be made with wearables in mind. Users will be able to download tens of thousands of apps directly from their wrist.
We’re just beginning to scratch the surface with wearables and mobile app integration. The coming years will be exceptionally progressive in this category.
While we’re not seeing a staggering jump year-year-over year, the growth is still steady. The wearables trend has changed and will continue to change the way that mobile apps get developed.
For instance, Apple made a big announcement about wearables and app integration at WWDC 2019. The new watchOS 6 has brought the Apple App Store to Apple Watch. Independent apps are being built specifically for these devices. This has created an enormous opportunity for app resellers and content creators.
In 2024, more mobile apps will be made with wearables in mind. Users will be able to download tens of thousands of apps directly from their wrist.
We’re just beginning to scratch the surface with wearables and mobile app integration. The coming years will be exceptionally progressive in this category.
5. Beacon Technology
Beacon technology has been embraced by a wide range of industries. From retail to healthcare and hospitality, beacons can add advanced functionality to nearly any mobile app. The first mobile app beacons were developed back in 2013. But over the last few years, significant advancements have been made to this technology. Here’s an example of how beacons work with mobile apps. Let’s say you’re a mobile app reseller that builds apps for retailers. Your clients can install beacons in their stores that connect with a user’s smartphone via Bluetooth if the app is on their device. When a user passes by a beacon, they can be instantly notified about a sale or special on products in that store. Beacons can also help track buyer behavior in stores. They can detect if a user is spending a significant amount of time in a particular aisle. The app can automatically trigger a push notification to entice a sale at a later date related to those products. The main benefit of beacon technology is proximity marketing. It ultimately improves the customer experience within a mobile app. According to Statista, the beacon technology market is increasing at a compound annual growth rate of 59.8%. The estimated market value will reach $56.6 billion by 2026. That’s more than ten times higher than the $519.6 million worth from 2016.6. Mobile Commerce
I can’t make a list of 2024 app trends without mentioning mobile commerce. This trend has been dominating for years, and will continue trending upward for the foreseeable future. It seems like everyone is leveraging mobile apps to increase revenue. From large retailers to individual content creators and personal brands, there is plenty of money to be made in this space. Mobile ecommerce functionality is a top feature for mobile app resellers to showcase during client pitches. It seems like every day another business is launching an app to drive sales. We’re not quite at this point yet, but we’re almost reaching the age where you need a mobile commerce app to stay competitive. Every single person and business selling online is competing with giants like Amazon. To keep pace, you need to replicate what makes those brands so successful; an app is at the top of that list. In 2021, more than 72.9% of total ecommerce sales came from mobile devices. Apps play a significant role in the current and future success of mobile commerce.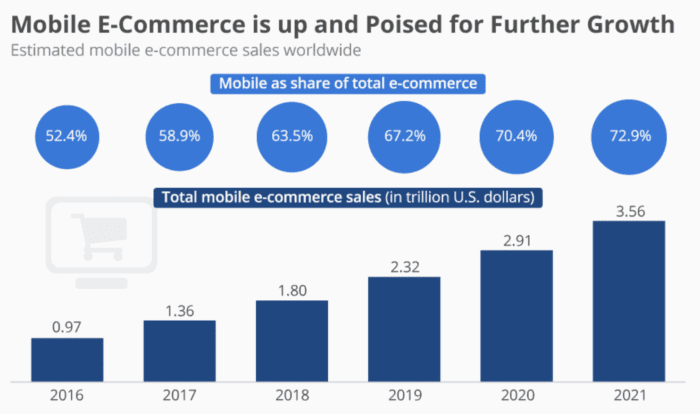 I could go on for days listing dozens of trends about mobile commerce. But in an effort to keep things brief here, you can check out our complete guide to mobile ecommerce statistics.
2024 will continue to be a big year for ecommerce app development. Plan accordingly.
I could go on for days listing dozens of trends about mobile commerce. But in an effort to keep things brief here, you can check out our complete guide to mobile ecommerce statistics.
2024 will continue to be a big year for ecommerce app development. Plan accordingly.
7. Artificial Intelligence (AI)
Artificial intelligence and machine learning both penetrated mobile app development years ago. But we’ve only just begun to scratch the surface with how these advanced technologies can be used. When we first think about AI, virtual assistants like Siri or Alexa come to mind. However, the use cases go far and beyond this for app development. Last year, Apple released Core ML 3. This latest version of the iOS machine learning framework was built to help developers embed AI technology into their apps. Examples of AI features that can be implemented into a mobile app include:- Image recognition
- Face detection
- Text and image classification
- Sentiment recognition and classification
- Speech recognition
- Predictive maintenance
8. Mobile Wallets and Mobile Payments
We’ve already discussed the role of mobile commerce for app development in 2024. But the way people pay using their mobile devices is evolving as well. Mobile wallets like Apple Pay, Google Pay, and Samsung Pay are trending upward. According to a recent report, there was $6.1 billion worth of transactions from mobile wallets in 2019. This is expected to reach $13.98 billion by 2023. In short, the mobile wallet market should double in the next two years. Smartphone users are slowly but surely adopting mobile payments. They’re even leveraging app functionalities for payments on connected wearable devices. In coming years, all the mobile apps out there need to account for mobile pay. Mobile wallets must be taken into consideration for app development in 2024. Wallet integration should become a standard feature for every app that processes transactions. Currently, that’s not the case. But the mobile wallet penetration rate in apps will grow significantly in the coming years.9. Augmented Reality (AR) and Virtual Reality
Augmented reality will continue trending upward in 2024. Mobile apps can use AR features for a wide range of use cases. Pokemon Go paved the way for AR in mobile app gaming. But today, the applications for AR have become more practical for other apps as well. L’Oreal Paris uses AR for their Style My Hair app.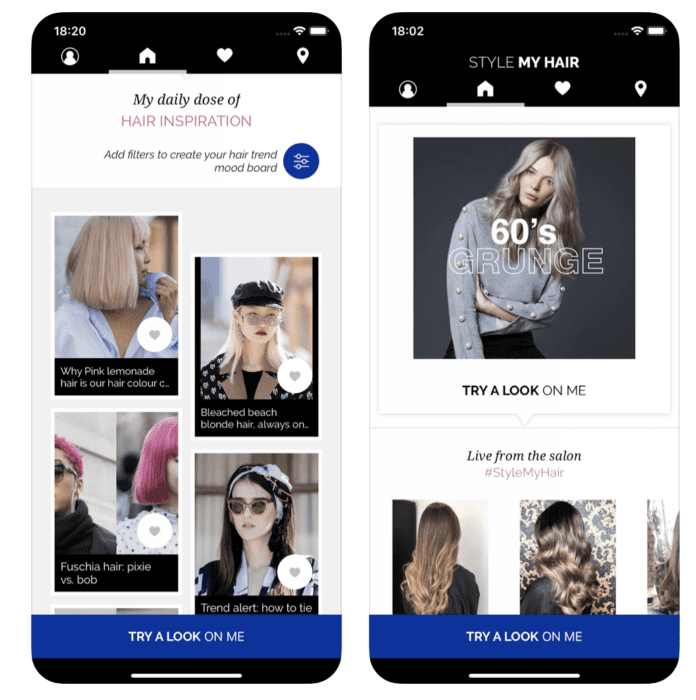 The app uses AR technology to showcase different hair styles and colors directly on the user. L’Oreal has also created a virtual makeup app using AR to see what makeup looks like on the user’s face.
Even Google Maps rolled out a feature called “Live View” where users can see turn by turn directions in real-time on real-world imagery. By pointing the device’s camera at buildings and street signs, the app can figure out exactly where a user is.
While these examples may not necessarily be useful for the majority of apps developed in 2024, there are plenty of other ways to use AR in mobile apps.
For example, workforce apps can use AR-based training programs for employee learning.
AR adaption is a top app development trend for content creators. You can use this technology to get creative as Instagram and Snapchat do with face filters.
Virtual reality is also shaking things up in the world of mobile application development. This is especially true for gaming apps. VR technology can connect with phones, apps, and wearables to enhance the gaming experience of fully functional mobile apps. In terms of virtual reality and AR, these mobile application development trends cannot be ignored if you’re in the industries mentioned above.
The app uses AR technology to showcase different hair styles and colors directly on the user. L’Oreal has also created a virtual makeup app using AR to see what makeup looks like on the user’s face.
Even Google Maps rolled out a feature called “Live View” where users can see turn by turn directions in real-time on real-world imagery. By pointing the device’s camera at buildings and street signs, the app can figure out exactly where a user is.
While these examples may not necessarily be useful for the majority of apps developed in 2024, there are plenty of other ways to use AR in mobile apps.
For example, workforce apps can use AR-based training programs for employee learning.
AR adaption is a top app development trend for content creators. You can use this technology to get creative as Instagram and Snapchat do with face filters.
Virtual reality is also shaking things up in the world of mobile application development. This is especially true for gaming apps. VR technology can connect with phones, apps, and wearables to enhance the gaming experience of fully functional mobile apps. In terms of virtual reality and AR, these mobile application development trends cannot be ignored if you’re in the industries mentioned above.
10. Chatbots
Chatbots have been around for more than a decade. I remember my first interactions with these bots in the late 1990s on AOL Instant Messenger. Over the years, chatbots have evolved and become much more advanced. Chatbots on websites have increased in popularity due to consumer demand. It’s becoming the new standard of customer service. But of the millions of apps available on the Apple App Store and Google Play Store, just a small fraction actually use chatbots. This will change in 2024. Since chatbots are driven by AI technology, their responses are becoming more human-like. We already discussed how AI will continue to trend upward, and this is one of the reasons why. The global chatbot market is growing at 24% each year. It’s expected that 25% of all customer service tech interactions were facilitated by virtual assistants in 2020. For this to happen, chatbots need to penetrate the mobile app development market.11. Superior App Security
Everyone is susceptible to cybercrime. From singular content creators to multi-billion dollar enterprises, nobody is immune. Malware attacks designed to harm mobile devices increased by 54%. More than 60% of fraud originates from mobile devices. Of that figure, 80% comes from mobile apps. From an app development standpoint, you can’t afford to take any shortcuts when it comes to securing your app. If you’re an app reseller, security needs to be a top priority for your clients as well. App users are well aware of security risks. So moving forward, people think twice about sharing passwords or providing sensitive information to third-parties, like app developers. Developers will start implementing features like Sign in With Apple to mobile apps. Rather than forcing app users to fill out form fields with their name, email address, and password, they can simply create an account and sign in using their Apple ID. These accounts are protected with two-factor authentication, and Apple won’t track the activity.12. Predictive Analytics
Here’s another mobile app development trend that will shake things up in the mobile app industry. By leveraging technology for machine learning, AI, data mining, and modeling, predictive analytics can forecast events using data. Tech giants have been leveraging predictive analytics for years now. A simple example is Netflix. The platform offers TV show and movie recommendations based on what users have previously watched. In 2024, predictive analytics will be implemented on a more mainstream level, for a wide range of mobile apps. The primary purpose will be to enhance the UI/UX with an app. Take a look at how businesses across the globe are using AI technology.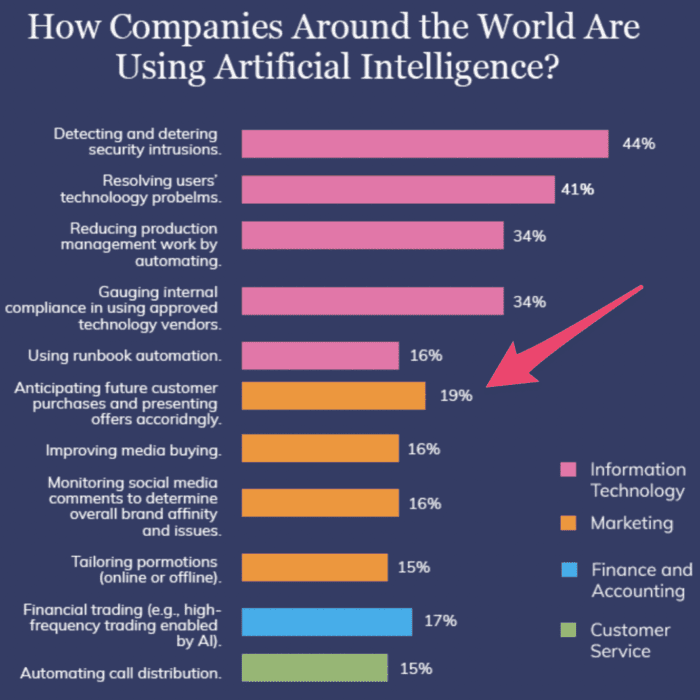 19% of companies use AI for predictive analytics, which ranks first in the marketing category and fifth overall.
The idea here is that no two users will have the same experience with an app. Product suggestions and preferences will be presented differently based on each user’s actions and behavior history.
19% of companies use AI for predictive analytics, which ranks first in the marketing category and fifth overall.
The idea here is that no two users will have the same experience with an app. Product suggestions and preferences will be presented differently based on each user’s actions and behavior history.
13. On Demand Apps
On-demand mobile app development is trending upward in 2024. Apps like Airbnb and Uber have shown how successful apps in this space can be. Users spend $57.6 billion per year using on-demand services. These are some examples of how apps can transform the on-demand industry:- Laundry service
- Doctors on-demand
- Virtual tutors and coaches
- Food delivery
- House cleaning
- Maintenance services
- Fitness on-demand
- Pet care
- Barber and beauty salon
14. Cloud Computing Integration
While cloud technology is not new, it hasn’t quite penetrated the mobile app industry to its full potential just yet. But this is a mobile app development trend that you definitely need to keep an eye on. Cloud computing has a wide range of possibilities for mobile development, which will be exploited in 2024. Cloud storage technology can improve the performance of mobile apps at the user’s end. Apps can store data and carry out complex tasks on the cloud, as opposed to storing information directly on the user’s device. Not only does this streamline development operations, but it’s also a cost-effective development solution. 83% of enterprise workloads are be cloud-based. If your agency is building business apps or internal workforce apps, you need to keep an eye on cloud computing trends in 2024.15. Instant Apps
Android Instant Apps launched a few years ago. But we’re going to see a rise in usage and development in 2024. Android Studio allows developers to build instant app experiences to improve their app discovery. Users can try the app without installing it. They just need to click on the “try now” button. Instant apps have size restrictions, so it won’t necessarily be a full version of the app. But these limitations could change in the coming years.
App users demand a better experience. Allowing them to use an app without downloading it is a great way to give them that.
Hollar, a mobile commerce app, was able to increase conversions by 20% by launching an instant app. 30% of their entire Android traffic comes from the instant app.
If you’re developing apps for the Google Play Store in 2024, you need to have an instant version as well.
Instant apps have size restrictions, so it won’t necessarily be a full version of the app. But these limitations could change in the coming years.
App users demand a better experience. Allowing them to use an app without downloading it is a great way to give them that.
Hollar, a mobile commerce app, was able to increase conversions by 20% by launching an instant app. 30% of their entire Android traffic comes from the instant app.
If you’re developing apps for the Google Play Store in 2024, you need to have an instant version as well.
Conclusion
Mobile app development is constantly changing. If you’re building apps today using information from two or three years ago, you won’t be able to stay competitive. Mobile app industry trends can make or break the success of your project. As a reseller or mobile app development company, you can treat the 2024 mobile app trends like your bible. This is how you can gain an edge in your space. All of the mobile app developers on your team need to understand mobile app development trends and incorporate them into the app development process. You don’t necessarily need to implement every single trend into every app you build. But you need to have a general understanding of how the market is shifting so you can adapt accordingly. Based on my extensive research, the 15 app development trends that I outlined above will dominate 2024.Frequently Asked Questions
How will 5G technology impact mobile app development in 2025?
5G technology will significantly enhance mobile app performance by providing faster speeds and lower latency.
What are the key considerations for developing apps for foldable devices?
Developers need to ensure that apps can seamlessly adjust their display as the screen folds or unfolds.
Why is IoT integration important for mobile apps in 2025?
IoT integration allows mobile apps to connect with a wide range of devices, enhancing user convenience and control.
What trends are influencing wearable app development?
Wearable app development is influenced by the steady growth of smartwatches and fitness bands, requiring apps to offer seamless integration and functionality.